research that ships,/* and research that scales */
My work spans two threads: building the datasets and benchmarks that make rigorous AI evaluation possible, and developing the core AIML methods that push the frontier. Below is a curated selection across both.
# datasets_benchmarks_evals
Datasets, Benchmarks & Evaluations
Before you can evaluate AI in the real world, you need the right data. These papers each introduce a new dataset, challenge, or evaluation framework — most have become standard references in their fields.
-
Most AI benchmarks are synthetic, static, and detached from economic reality. UpBench changes that. It grounds agentic AI evaluation in 322 real, economically verified jobs from the Upwork labor marketplace — each tied to an actual client transaction with real financial outcomes. Expert freelancers decompose jobs into rubric criteria and evaluate AI submissions with per-criterion feedback, enabling fine-grained analysis far beyond binary pass/fail. The benchmark refreshes dynamically to mirror how real work evolves.
-
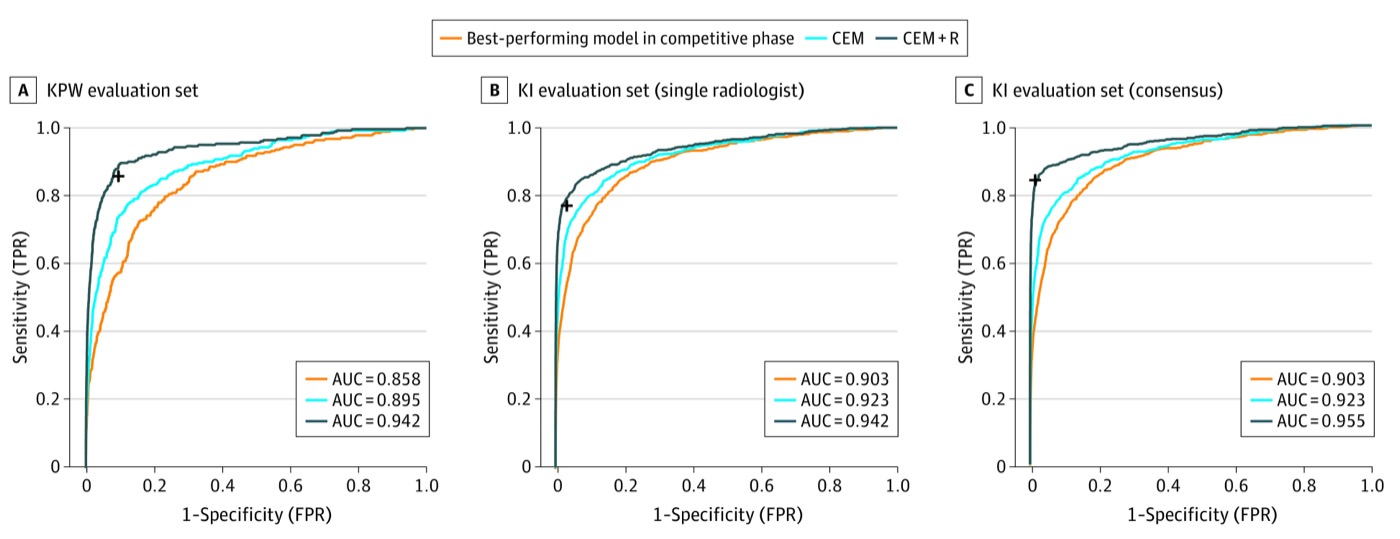
An international crowdsourced challenge — 126 teams from 44 countries — evaluated on 144,231 mammograms from 85,580 US women and independently validated on 166,578 Swedish mammograms. Finding: no single AI algorithm outperformed community radiologist benchmarks, but human–AI combinations showed measurable gains. A landmark result that shaped subsequent AI-in-mammography policy worldwide.
-
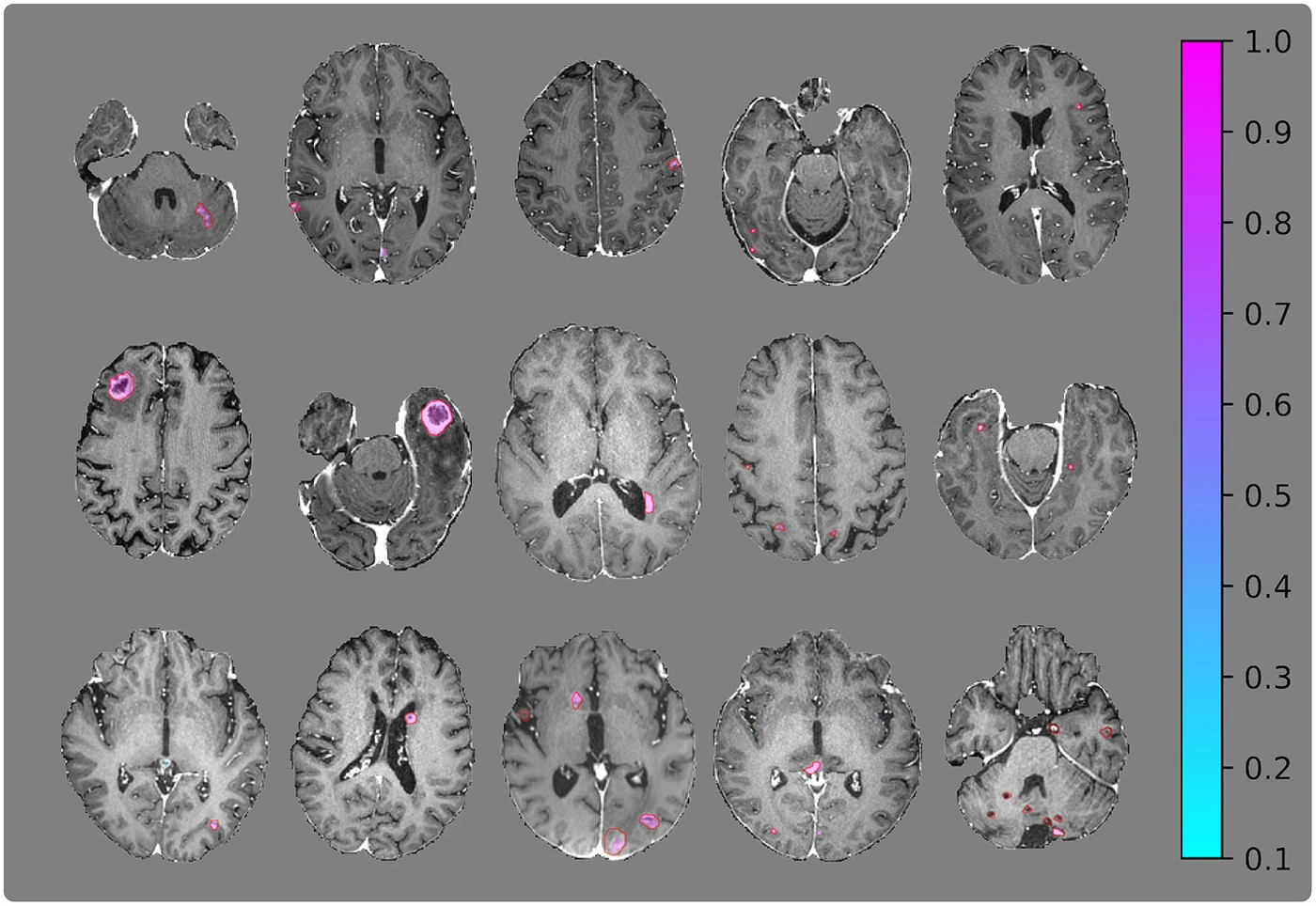
156 whole-brain MRI studies across 4 sequences. The companion dataset BrainMetShare was released through Stanford AIMI and has become the standard benchmark for brain metastasis segmentation — cited by dozens of follow-on papers. AUC 0.98 overall, 0.99 for patients with 1–3 metastases, demonstrating strong performance across all lesion burden categories.
-
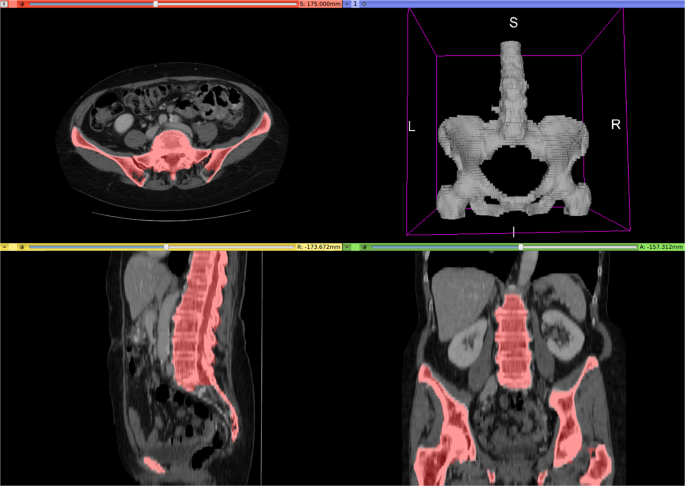
140 diverse CT scans across six organ classes (liver, lungs, bladder, kidney, bones, brain). Annotation accelerated via unsupervised morphological segmentation and 3D Fourier transforms. A deep network trained on this data segments all organs in 4.3 seconds. Released through TCIA — a standard multi-organ benchmark used across dozens of subsequent papers.
-
Trained on 216,431 frontal chest X-rays from Stanford (1998–2012). Key finding: CNN alone achieves AUC 0.96, but combining CNN output with physician judgment achieves AUC 0.98 — outperforming either alone. Also maps the effect of training set size, architecture choice, and initialization strategy, providing a practical blueprint for clinical deployment decisions.
-
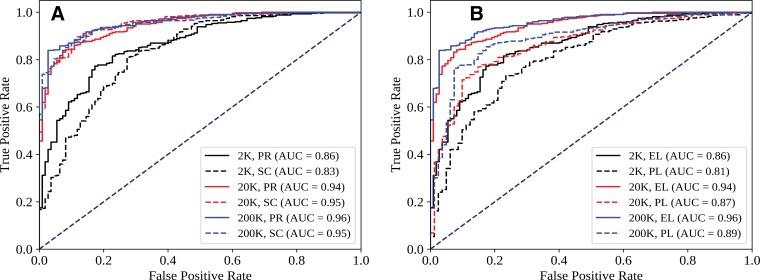
An annotated dataset for periorbital segmentation — enabling AI analysis of eyelid and periocular anatomy for ophthalmic surgical planning and disease monitoring. Developed at the UIC Ai-O Center as a resource for the ophthalmic AI community.

-
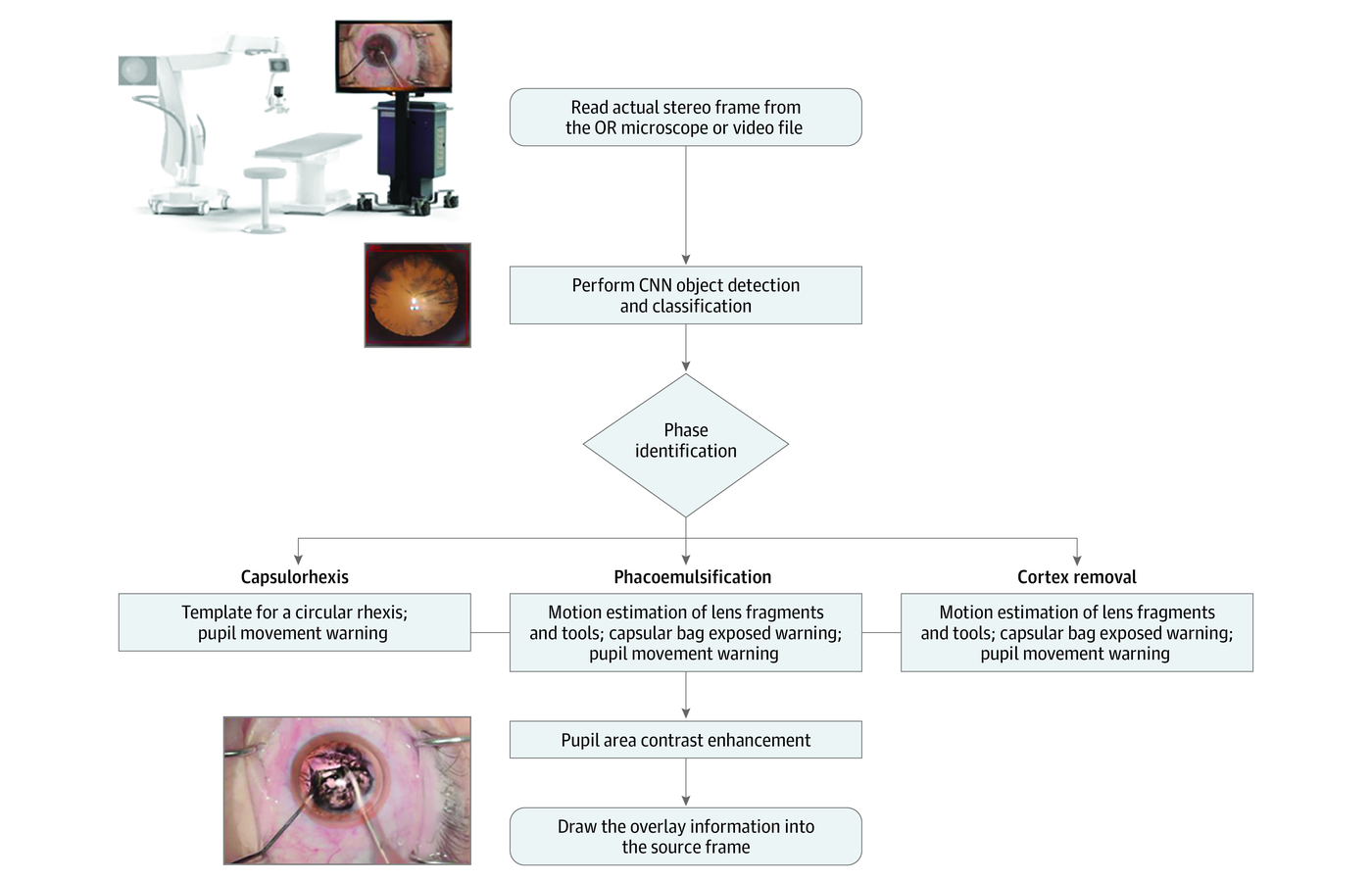
Evaluation of AI-guided tools for intraoperative decision support in ophthalmology — assessing how computer vision assistance integrates into surgical workflow and supports real-time clinical decisions during eye surgery. Covers both phacoemulsification cataract surgery (JAMA Ophthalmology) and vitreoretinal procedures (TVST).
-
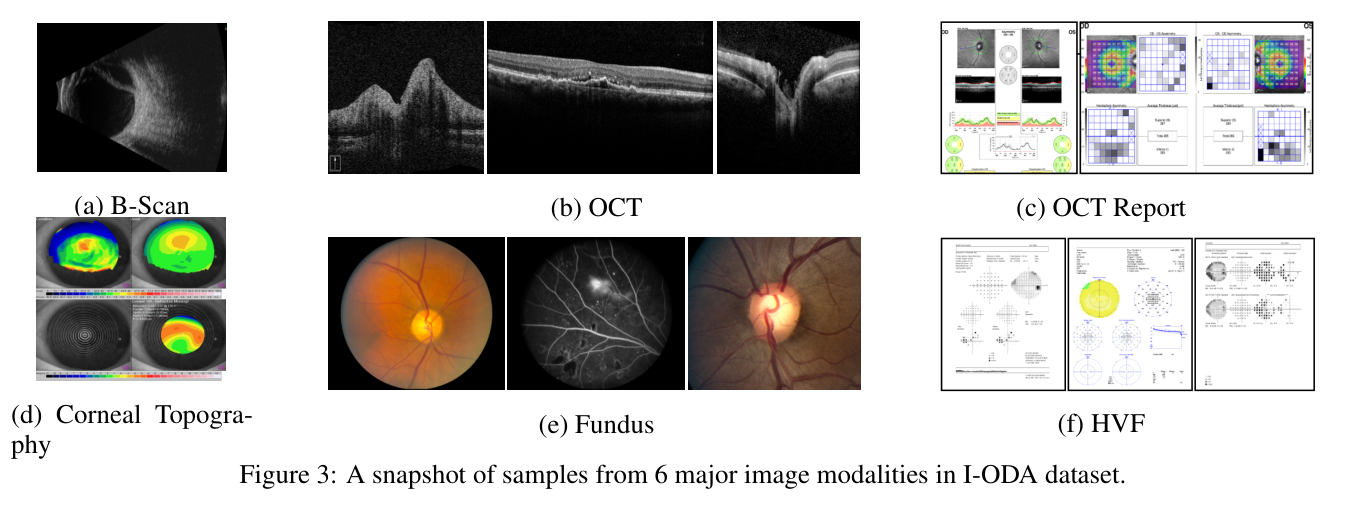
A large-scale structured ophthalmic data atlas aggregating 12 imaging modalities with 3.6M+ images of 33,876 individuals — retinal photography, OCT, visual fields, and more — collected over 12 years at UIC. Supports AI research across ophthalmic disease areas. One of the largest annotated ophthalmic datasets assembled for machine learning research.
-
Establishes that sharing model weights (not patient data) across institutions trains collaborative deep learning models with performance comparable to centralized training — while fully preserving patient privacy. One of the foundational results in federated medical AI, cited across hundreds of subsequent papers.
# foundational_aiml
Foundational AIML Contributions
Core methods work: pulse sequence integration for MRI, federated learning without data sharing, GAN-based augmentation, robust training under noisy labels, and distributed deep learning for multi-institutional AI.
-
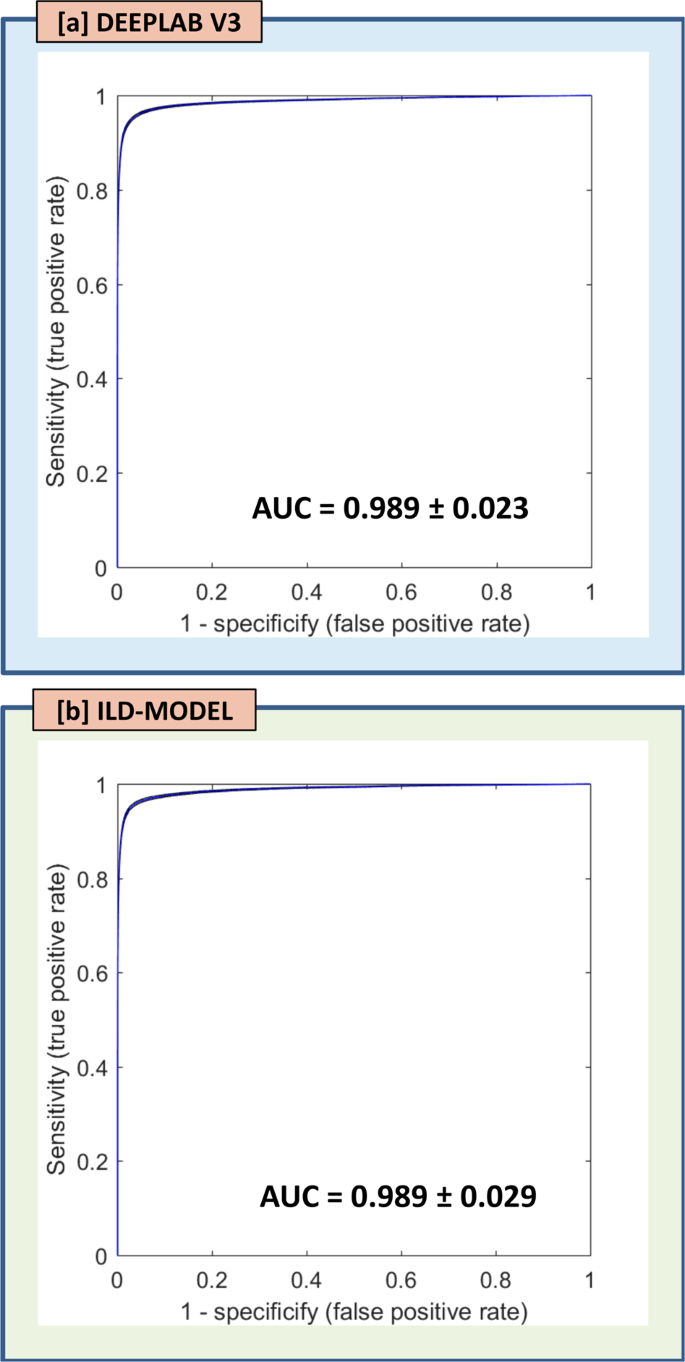
A multi-institutional clinical validation of deep-learning brain-metastasis segmentation that stays robust when MRI pulse sequences are missing at inference. Using input-level dropout — training across subsets of the four input sequences — the model matches a full-input DeepLab V3 network, both reaching AUC ≈ 0.99 for lesion detection across sites. A practical result for deploying medical AI in real hospitals, where complete, standardized MRI protocols are rarely available.
-
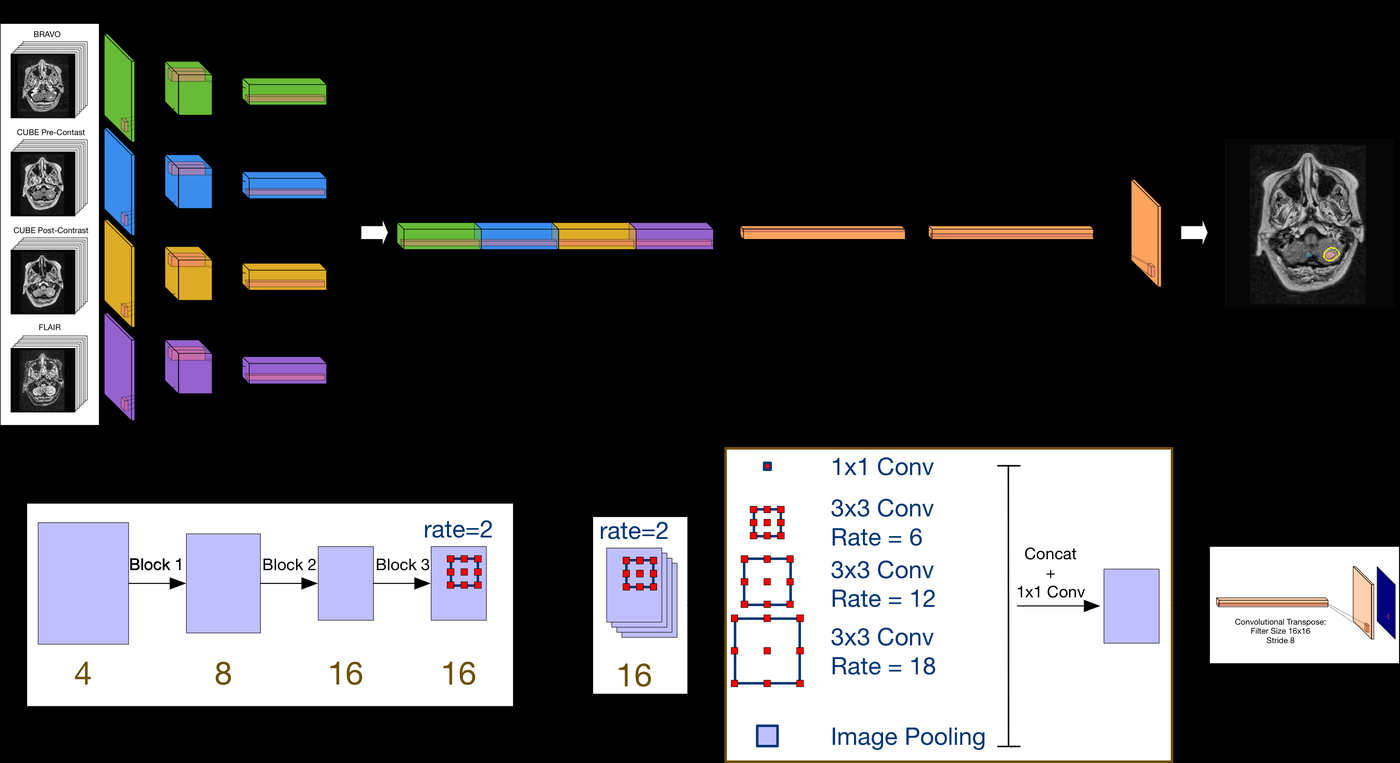
Systematically evaluates how to integrate multiple MRI pulse sequences in deep learning architectures: early fusion, late fusion, and parallel-branch with weight sharing. Introduces input-level dropout (ILD) — trains on all 15 possible subsets of 4 input sequences simultaneously — making the model robust to any missing sequence at inference time, a critical property for clinical deployment.
-
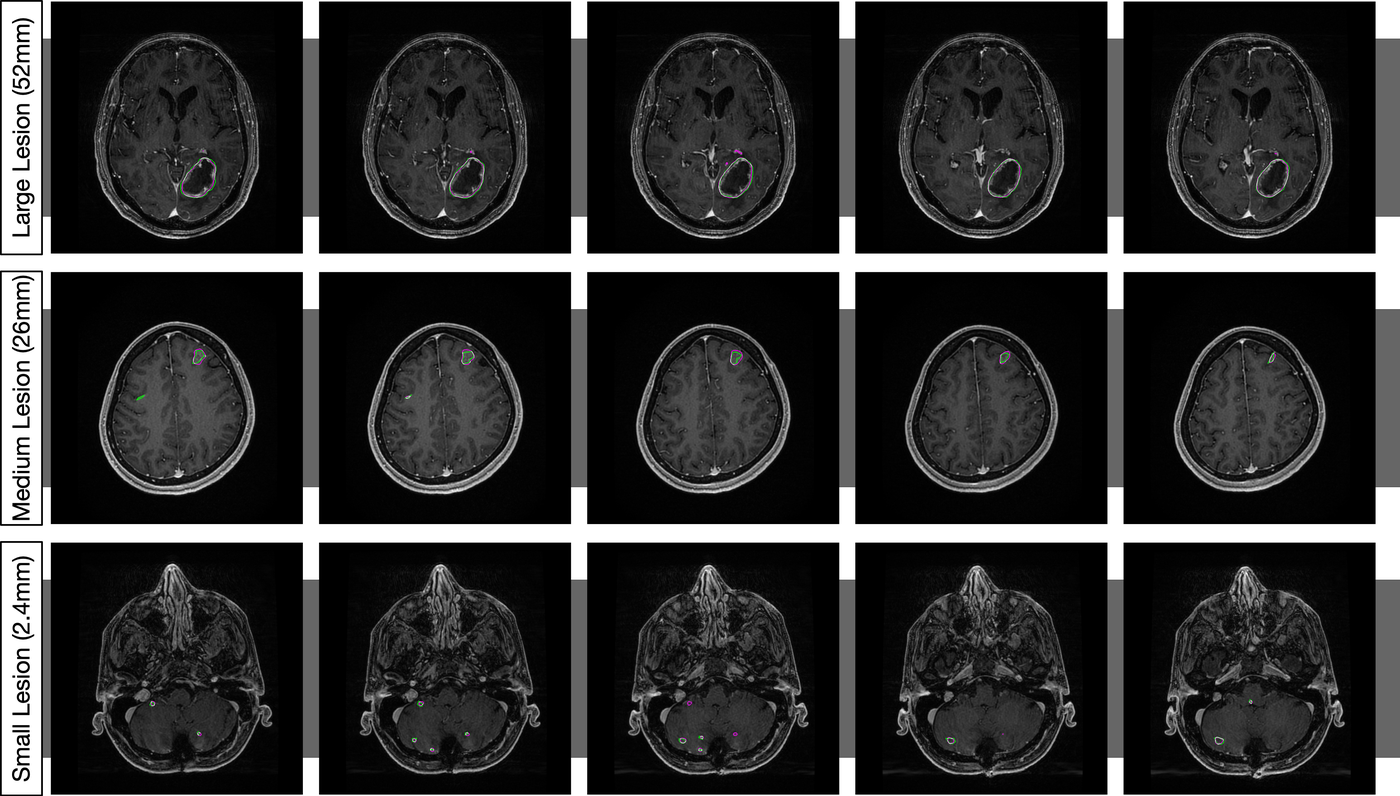
Radiologist annotations systematically miss small metastases — training naively on such data teaches the model the same blind spots. Proposes modified loss functions and annotation-uncertainty weighting for robust training under systematic false negative noise. Lopsided bootstrap loss retains sensitivity at 97% of baseline under 50% random censoring, and improves performance from 17% to 88% under size-based censoring.
-
Explores whether GAN-generated synthetic retinal images can augment training data for diabetic retinopathy grading — and under what conditions synthetic augmentation helps vs. hurts model performance. Presented at the CVPR 2024 DCAMI workshop, bridging generative AI methods with clinical vision tasks.
-
Deep-learning glaucoma classifiers perform well in-distribution but lose robustness under domain shift — e.g. fundus images from a different hospital or population. This work adds an adversarial domain-adaptation branch that strips domain-specific signal so the network learns domain-invariant features, training jointly on glaucoma classification and domain discrimination. Across LAG, REFUGE, and University of Illinois Chicago fundus sets, it improves cross-domain accuracy by roughly 6–12 points over a source-only ResNet-50 baseline. Presented as an ARVO Annual Meeting abstract in Investigative Ophthalmology & Visual Science.
-
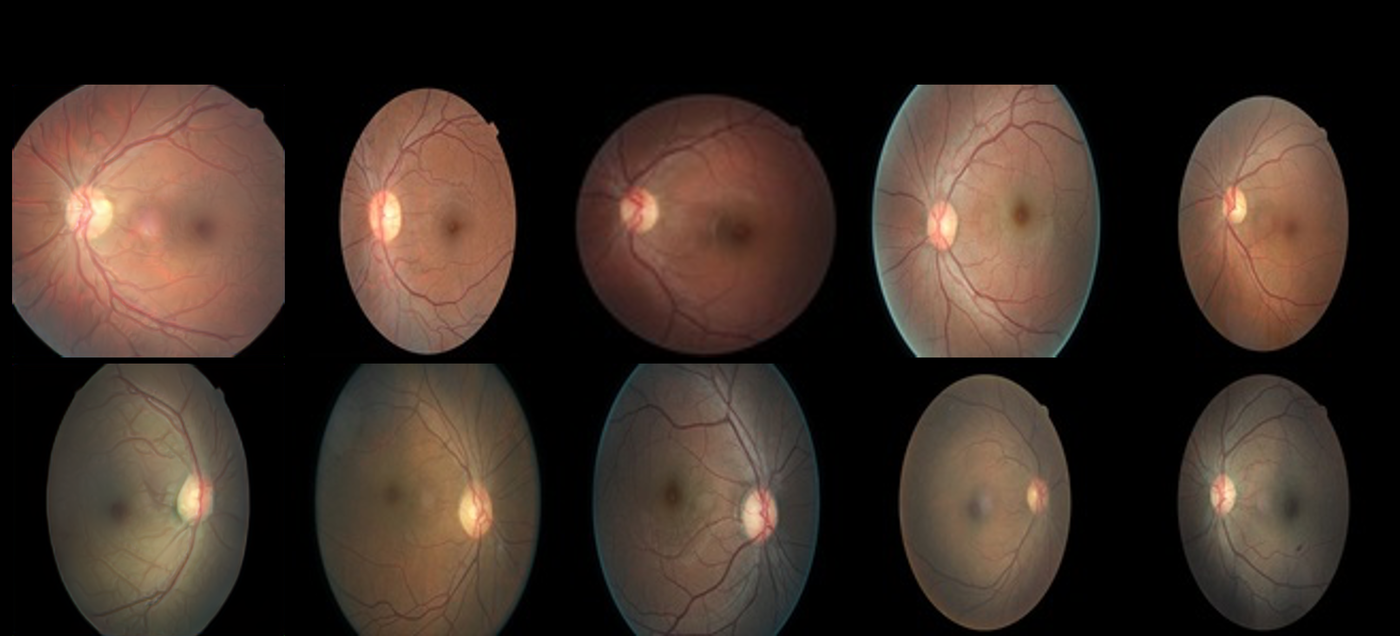
Systematic evaluation of how AI models trained in one ophthalmic setting perform when deployed on real-world clinical data from a different institution or population. Tests generalizability gaps — the common failure mode where models degrade between development and clinical deployment — and proposes strategies to close them.
-
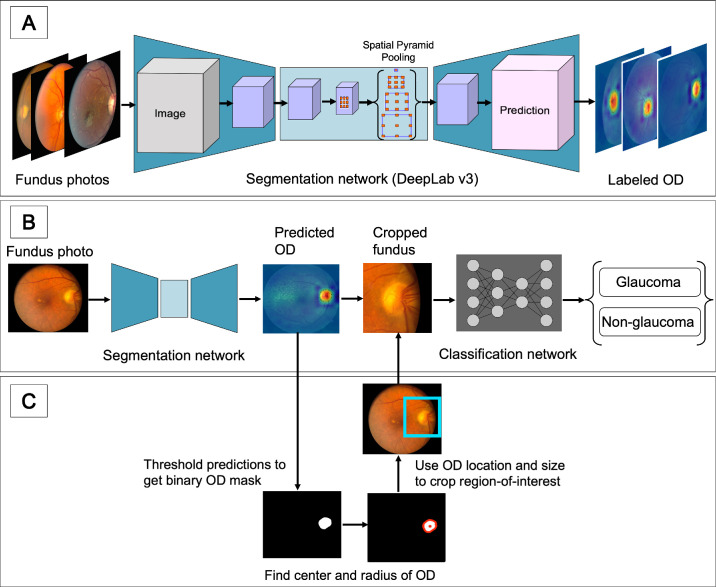
Standard classifiers are over-confident on inputs unlike anything seen in training — a real risk for clinical deployment. This work adds an uncertainty-learning "Dirichlet" head onto a CNN feature extractor that flags unreliable, out-of-distribution samples while still classifying fundus images as glaucoma or non-glaucoma. Trained on Illinois Eye & Ear Infirmary fundus images and stress-tested against REFUGE, LAG, and non-medical datasets, it improves OOD detection over a softmax baseline while keeping competitive glaucoma AUC. Presented as an ARVO Annual Meeting abstract in Investigative Ophthalmology & Visual Science.
-
Proposes CvS, a classifier for small datasets that derives classification labels from predicting segmentation maps. Uses label propagation to create fully segmented datasets from minimal manual annotation, then trains classifiers via the segmentation pathway — demonstrating improved classification accuracy when labeled training examples are scarce, directly applicable to ophthalmic imaging tasks.
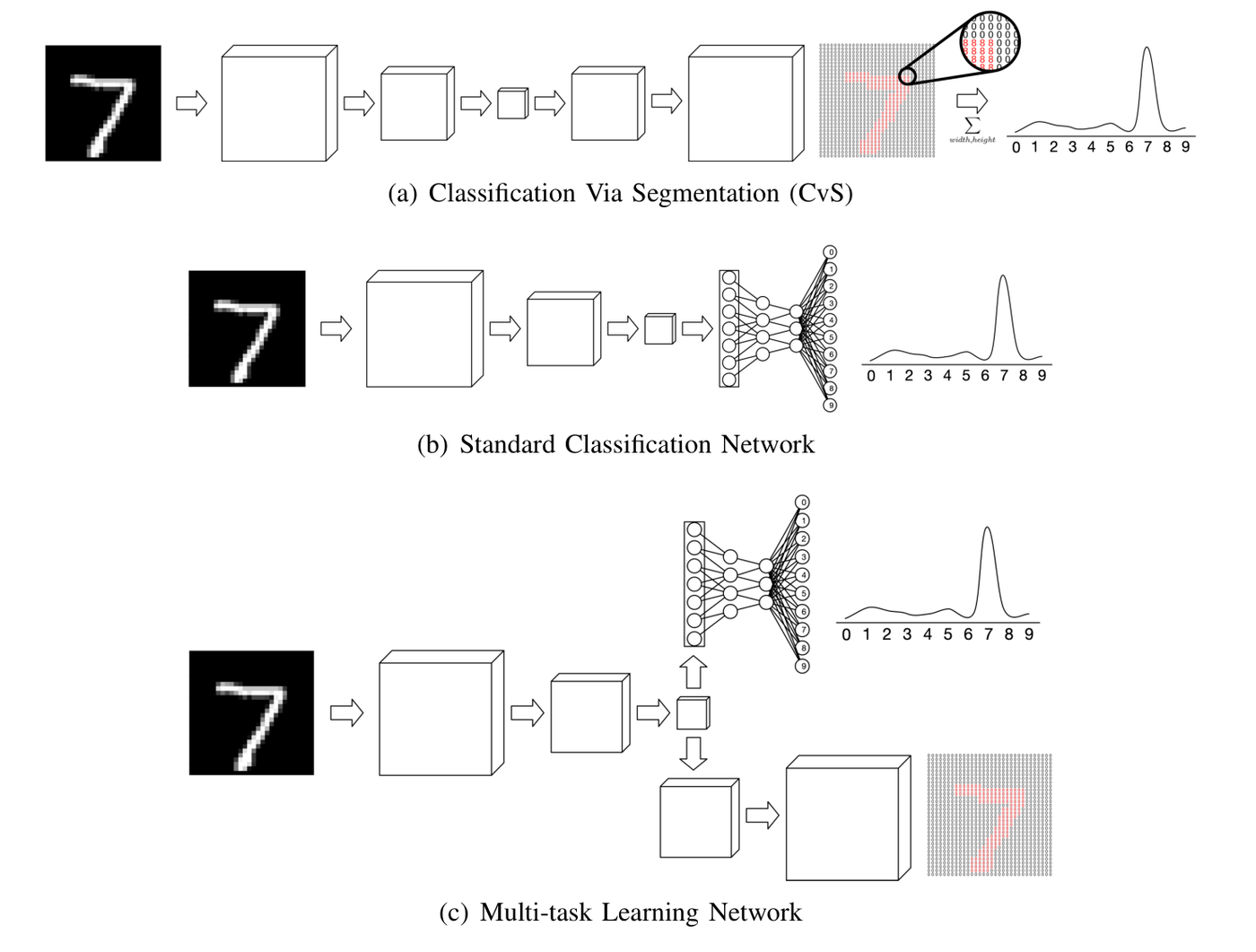
-
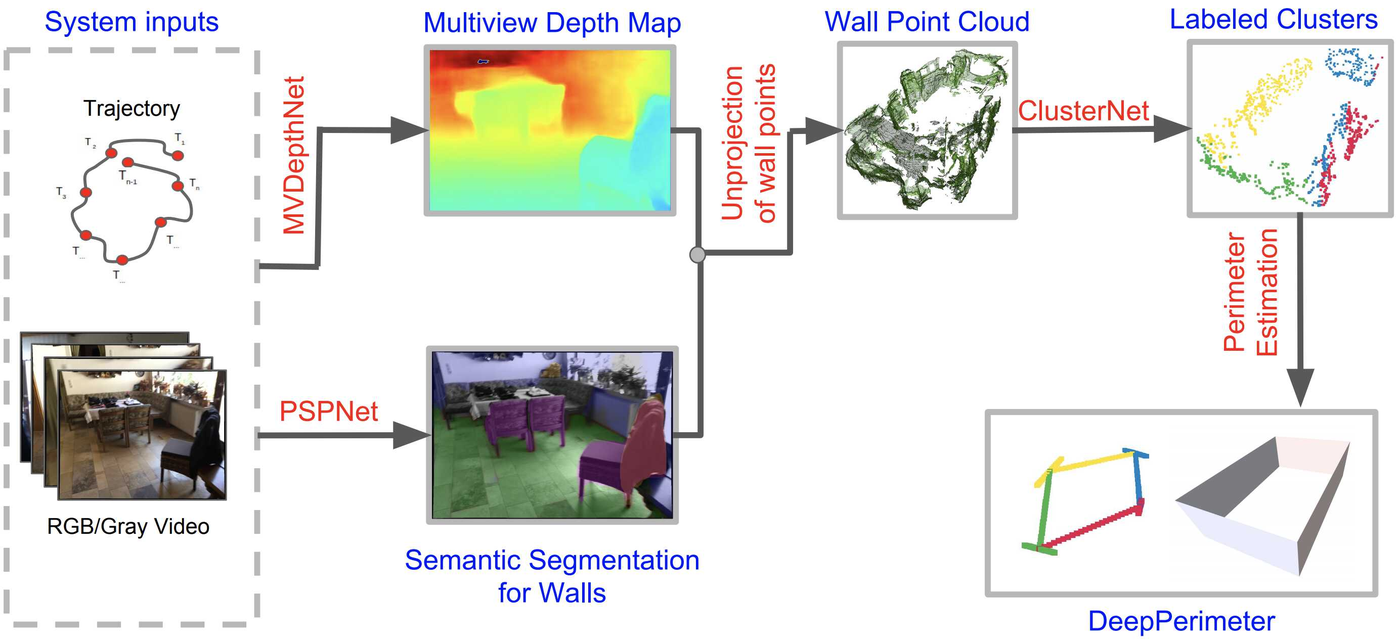
A deep learning pipeline for extracting indoor room perimeters from RGB image sequences with known camera poses. Combines robust deep methods for depth estimation and wall segmentation to create boundary point clouds, then applies unsupervised clustering to fit wall planes — robust perimeter extraction across diverse room layouts, with applications in augmented reality and robotics. Benchmarked on ScanNet and FloorNet datasets.